Thanks for your feedback!
EDIT
As agregações otimizam a realização de buscas complexas, tornando-as mais rápidas e fáceis. Várias buscas podem ser agregadas, sendo realizadas e exibidas como uma única requisição e resultado final. Isso aumenta a performance e melhora a experiência do usuário. Em comparação com buscas (queries), agregações consomem mais CPU e memória.
Toda agregação é uma combinação de um ou mais buckets e zero ou mais metrics.
A seguir, veja mais sobre:
Buckets criam grupos de documentos com base em um determinado critério, dependendo do tipo de agregação. O conceito vem da ideia de agrupar os documentos em baldes (tradução de buckets). Buckets não calculam métricas, como fazem as metrics.
Como exemplos de agrupamento em buckets: a data 2022-12-19 estaria no bucket (balde) de December (dezembro) e a cidade de Campinas, no bucket do estado de São Paulo.
Buckets podem estar contidos dentro de outros buckets. Por exemplo, Campinas entraria no bucket do estado de São Paulo e todo o bucket de São Paulo estaria no bucket do Brasil.
Veja na tabela a seguir a descrição dos principais tipos de buckets. A imagem abaixo mostra uma parte da tela Visualize com a lista para escolher o tipo de bucket. Veja também como criar uma nova visualização e saiba como chegar nesta tela para escolha do tipo de bucket.
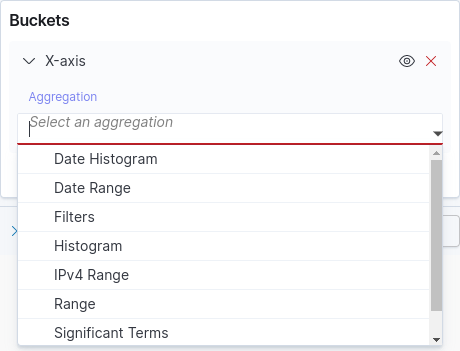
Tipo |
Definição |
Parâmetros |
Histogram (histograma) |
Agrupa os documentos em buckets dinamicamente, com base em intervalos específicos (valores numéricos ou intervalos numéricos). Similar à agregação por range; porém, ao invés de determinar cada intervalo especificamente, você pode ativar a opção |
Minimum interval: selecione Use auto interval ou especifique o intervalo mínimo. |
Date histogram (histograma de datas) |
Semelhante ao histograma simples, porém, usado apenas com valores de datas ou intervalo de datas. |
Minimum interval: especifique o intevalo mínimo de arredondamento. Por padrão, |
Range (intervalo) |
Define um conjuto de intervalos, cada um representando um bucket. Cada documento é verificado de acordo com a faixa de variação do seu intervalo e agrupado conforme sua relevância ou correspondência a essa faixa, que pode ser numérica, de datas ou de endereço de IP. Exemplo de uso: na busca por determinado tipo de produto em uma loja online, range pode exiber a faixa de preços mais popular para aquele tipo de produto. |
|
Date range (intervalo de datas) |
Agregação de range (intevalo) específico para datas. |
Acceptable date formats: determine o início e fim do intevalo. |
Filters (filtros) |
Agregação na qual cada bucket contém documentos que correspondem a uma busca. É possível definir mais de um filtro. |
Filter: forneça a expressão de busca. Pode ser escrita em DQL ou Lucene. Clique em + Add filter para adicionar mais outro filtro. |
NOTE: Selecione Lucene ou DQL e utilize a sintaxe correspondente. Para que uma query escrita em Lucene seja interpretada corretamente, é necessário selecionar Lucene. O mesmo é válido para DQL. |
||
Terms (termos) |
Agrupa por categorias e recupera o total de documentos de cada categoria. Ou seja, terms informa o número de vezes que determinado termo aparece nos seus documentos. |
Order by define o tipo de ordenação com base na métrica (metrics) selecionada, podendo ser: |
Significant terms (termos importantes) |
Retorna ocorrências de termos interessantes ou incomuns. O resultado mostrado é a diferença entre a ocorrência de um termo em todo índice e a ocorrência do mesmo termo nos resultados das suas buscas (queries), destacando os termos que são relevantes dentro de cada contexto de busca. Por exemplo, o termo "sensedia" seria relevante no contexto de "apis". |
Size: defina quantos term buckets devem ser retornados da lista total de terms. |
Tanto as agregações metrics como buckets permitem que você adicione parâmetros avançados.
Para acessar os parâmetros avançados, clique no ícone para expandir/recolher ao lado de Advanced (imagem abaixo).
Dependendo do tipo ou campo selecionado para a agregação, além do campo para inserção em formato JSON, diferentes opções podem estar disponíveis para entrada ou seleção de dados.
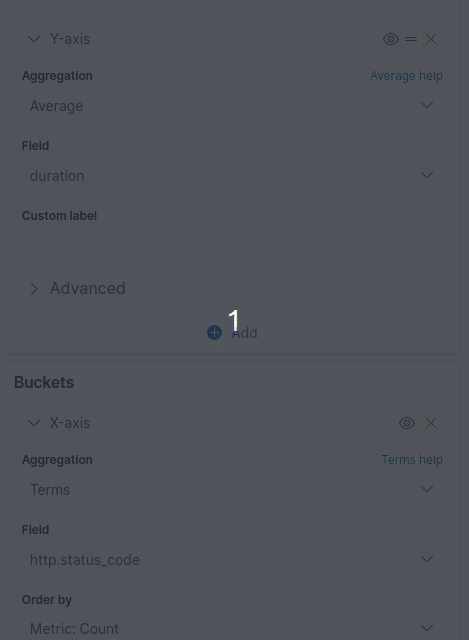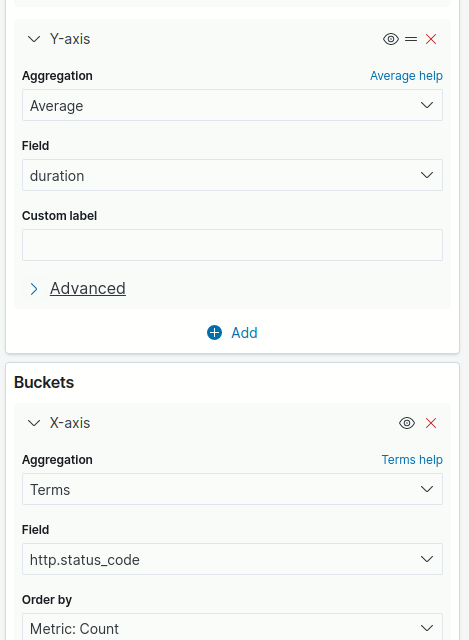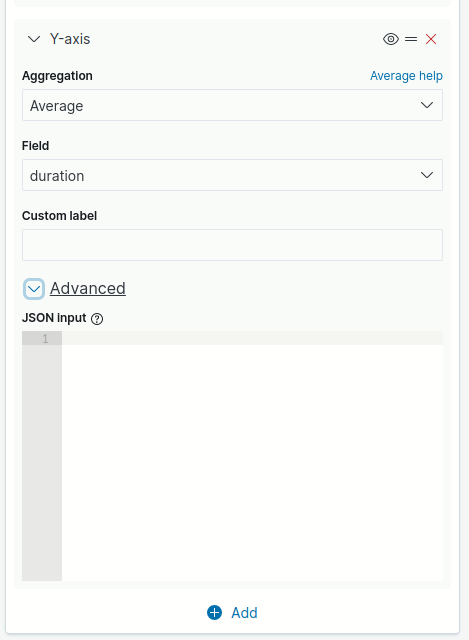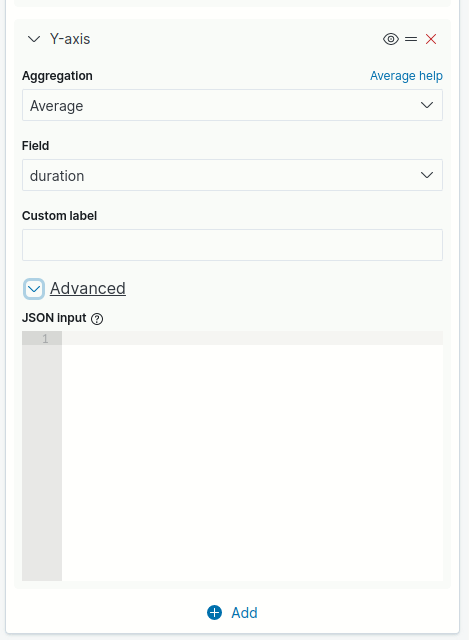
Veja na tabela abaixo definições e exemplos de uso para os principais parâmetros avançados de agregações bucket.
As definições de cada tipo de agregação bucket e seus parâmetros básicos estão na tabela anterior.
Tipo |
Parâmetros avançados |
Date histogram |
|
Range e Date range |
"missing": "1976/11/30",
"ranges":[
{
"key": "Older",
"to": "2015/01/01"
},
]
|
Filters |
|
Histogram |
"histogram": {
"field": "quantity",
"interval": 10,
"missing": 0
}
"extended_bounds" : {
"min" : "2014-01-01",
"max" : "2014-12-31"
}
|
Terms e Significant terms |
|
Agregações do tipo Metrics extraem estatísticas a partir de documentos agrupados em um ou mais buckets, ou de buckets vindos de outras agregações. Em linhas gerais, metrics geram um ou mais números que descrevem os documentos agrupados.
Metrics podem ser do tipo:
Single-value: retorna apenas uma métrica.
Multi-value: retorna mais de uma métrica.
Veja na tabela a seguir uma breve descrição de cada agregação metrics. A imagem abaixo mostra a parte da tela Visualize onde é feita a escolha da agregação metrics.
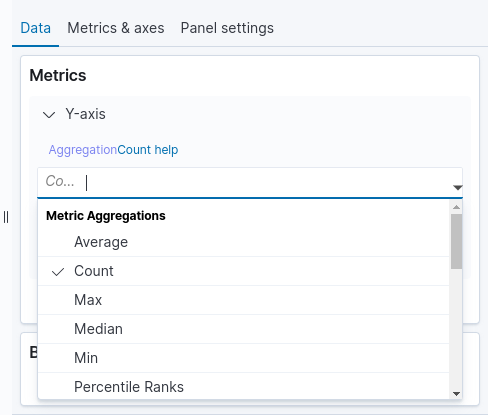
Metrics |
Descrição |
Average (média) |
Agregação de métrica do tipo |
Count (contagem) |
Esta métrica conta os documentos presentes em cada um dos buckets selecionados. |
Sum (soma) |
Agregação de métrica do tipo |
Max |
Agregação do tipo |
Median (mediana) |
Agregação do tipo |
Min |
Agregação de métrica do tipo |
Percentiles (percentis) |
Agregação de métrica do tipo |
Percentile ranks |
Agregação de metrics do tipo |
Standard deviation (desvio padrão) |
Representa a variação de um grupo de valores em torno da média. Um baixo desvio padrão indica que os valores tendem a estar próximos da média ou do valor esperado. |
Top hits |
Agregação de metrics do tipo |
Unique count |
Agregação de metrics do tipo |
Com pipeline aggregations você pode concatenar agregações usando os resultados de uma agregação como entrada para outra agregação.
Pipeline aggregations possibilitam cálculos estatísticos mais complexos, como derivadas, somas cumulativas e médias móveis.
Parent pipeline: pipeline aggregation na qual resultados de uma agregação pai são usadas para calcular novos buckets ou novas agregações que serão adicionadas aos buckets existentes. É necessário que o min_doc_count para o parent pipeline seja 0, que é o valor padrão para agregações do tipo histograma. A métrica deve ser com base em valores numéricos.
Sibling pipeline: pipeline aggregation na qual os resultados de uma agregação irmã são usados para calcular uma nova agregação que estará no mesmo nível da agregação irmã. Necessariamente, sibling pipelines são do tipo multi-value e a métrica deve ser um valor numérico.
As agregações pipeline encontram-se na mesma lista de agregações Metrics, como mostra a imagem abaixo.
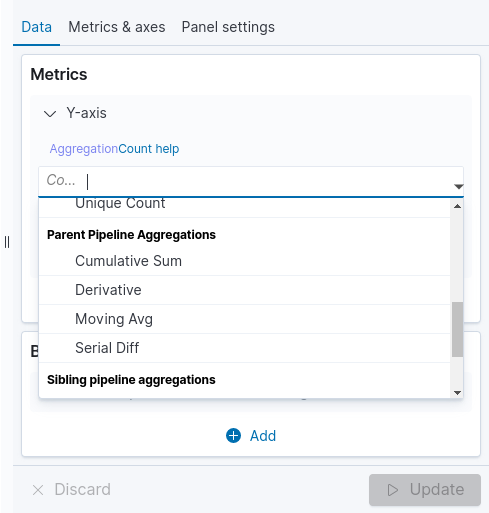
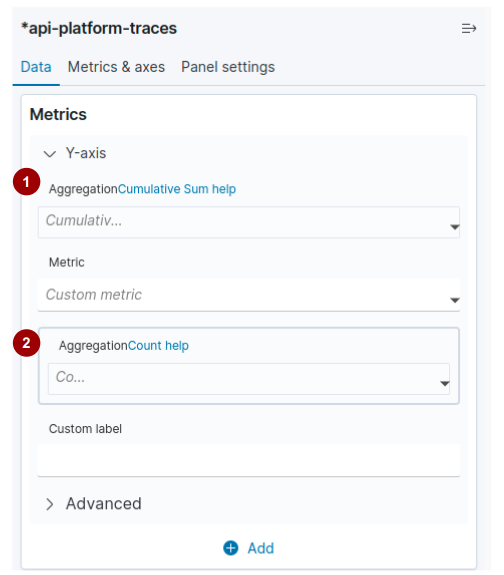
Ao selecionar uma agregação pipeline (identificado como 1 na figura abaixo), seja ela pai ou irmã, outra caixa se abre abaixo para que você possa configurar a segunda agregação (identificado como 2 na figura abaixo):
Parent pipeline aggregations
Agregação |
Descrição |
Cumulative sum soma cumulativa |
Calcula a soma cumulativa de uma métrica em uma agregação do tipo histograma ou date histogram pai. Esta agregação calcula o valor do campo somando o valor anterior com o atual. O resultado será um único valor representando a soma cumulativa dos valores do campo. A métrica deve ser numérica e o histograma adicionado deve ter o |
Derivative derivada |
Calcula a derivada de uma métrica em uma agregação do tipo histograma ou date histogram pai. A métrica deve ser numérica e o histograma adicionado deve ter o |
Moving avg média móvel |
Encontra as séries de médias de diferentes subgrupos (janelas) de um dataset. Pode ser usado para suavizar flutuações ou destacar tendências ou ciclos nos dados do tipo time_series. |
Serial diff |
Serial differencing é uma técnica que subtrai um valor em uma série temporal de si mesmo em um intervalo ou período diferente. Primeiramente, é necessário especificar um histograma ou date_histogram para um campo. Em seguida, pode-se adicionar uma métrica simples, como sum (soma) dentro do histograma, para então incluir o serial_diff no histograma. |
Sibling pipeline aggregations
Agregação |
Descrição |
Average bucket |
Calcula o valor médio de uma métrica específica em uma agregração do tipo sibling. A métrica deve ser numérica e a sibling aggregation deve ser do tipo |
Max bucket |
Identifica o(s) bucket(s) com o valor máximo de uma determinada métrica em uma agregação irmã e devolve o valor e a chave do(s) bucket(s). A métrica deve ser numérica e a agregação irmã deve ser do tipo |
Min bucket |
Identifica o(s) bucket(s) com o valor mínimo de uma determinada métrica em uma agregação irmã e devolve o valor e a chave do(s) bucket(s). A métrica deve ser numérica e a agregação irmã deve ser do tipo |
Sum bucket |
Calcula a soma entre todos os buckets de uma determinada métrica em uma agregação irmã. A métrica deve ser numérica e a agregação irmã deve ser do tipo |
Share your suggestions with us!
Click here and then [+ Submit idea]