Thanks for your feedback!
EDIT
O interceptor Rate Limit AI Tokens pode ser usado em proxies de APIs que consomem Grandes Modelos de Linguagem (Large Language Models - LLMs) para controlar o consumo de tokens pelas aplicações de inteligência artificial. Assim, é possível aumentar a eficiência do negócio, gerenciando melhor os custos dessas aplicações e impedindo excessos no uso, além de manter a qualidade do serviço evitando sobrecargas nos sistemas de inteligência artificial.
A seguir, você aprenderá como incluir o interceptor Rate Limit AI Tokens no fluxo de suas APIs e como configurá-lo.
O interceptor Rate Limit AI Tokens permite que você defina a quantidade máxima de tokens permitidos em um período de tempo. Quando esse limite for excedido, a chamada será negada e uma resposta com o código HTTP 429 será retornada ao cliente. É possível definir um percentual adicional de chamadas a serem aceitas para além do limite especificado e também optar por enviar no header da resposta um parâmetro com a quantidade de tokens restantes.
|
A contabilização de tokens realizada pelo interceptor Rate Limit AI Tokens é apenas uma estimativa, funcionando de modo semelhante à ferramenta OpenAI Tokenizer. Assim, caso sua API esteja diretamente conectada ao body enviado ao LLM, o valor calculado pelo interceptor poderá não coincidir com o computado pela API da OpenAI. Isso pode ocorrer devido ao fato de a API da OpenAI, além da string correspondente ao conteúdo da mensagem (prompt), também levar em consideração no cálculo de tokens consumidos outros elementos presentes no body da requisição. A própria OpenAI adverte neste artigo sobre a dificuldade em estimar o número de tokens. |
O interceptor pode ser incluído nos fluxos de requisição (REQUEST TO BACKEND) de uma revision de API ou de um plano, para todos os recursos (resources) e operações (operations) ou para recursos e operações específicos.
| Veja mais sobre fluxos de API. |
Para inserir o interceptor Rate Limit AI Tokens no fluxo, clique sobre seu ícone, localizado na categoria AI na tela Edit Flow, e arraste-o até o fluxo de requisição (REQUEST TO BACKEND), como na animação abaixo:
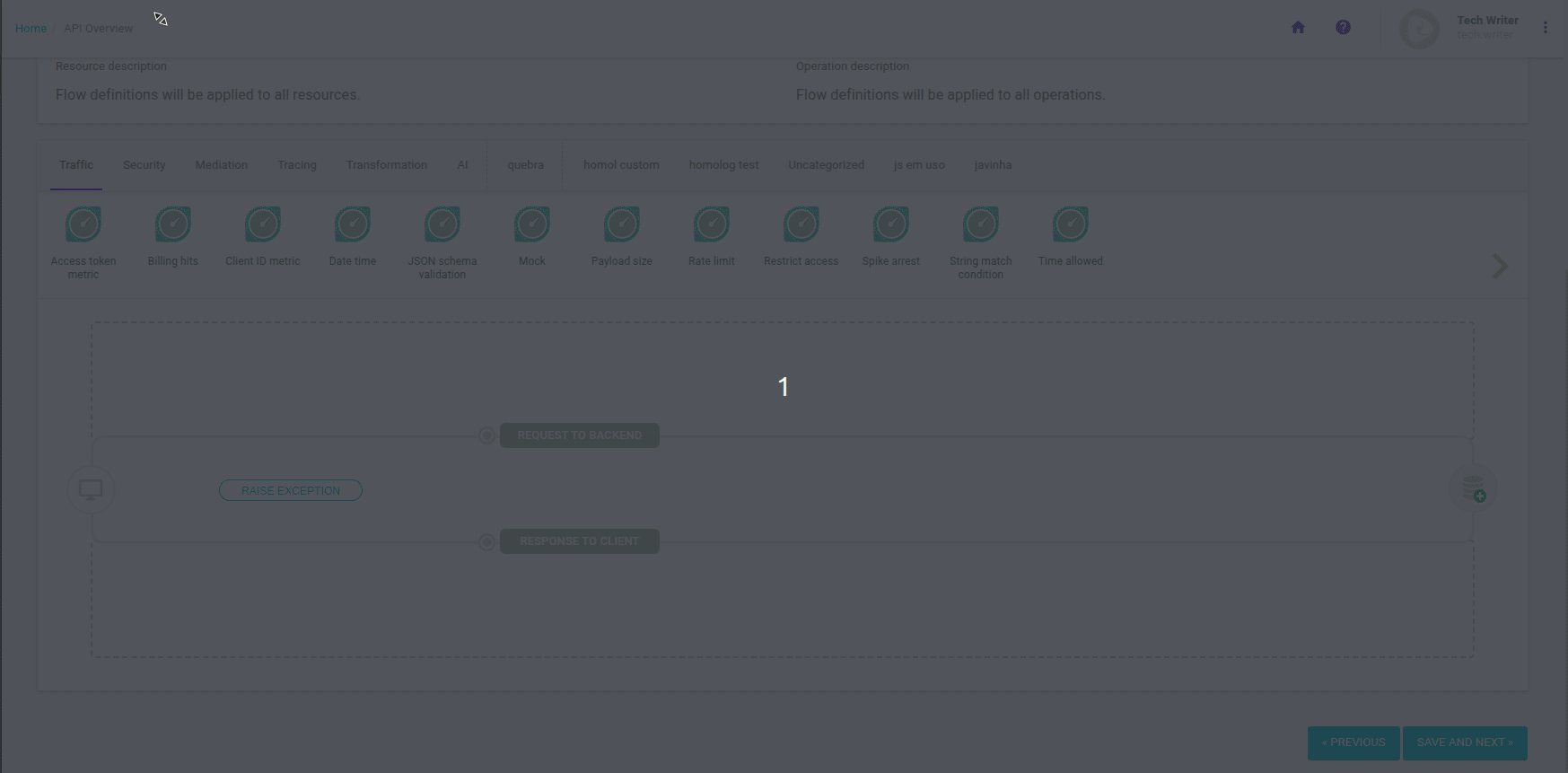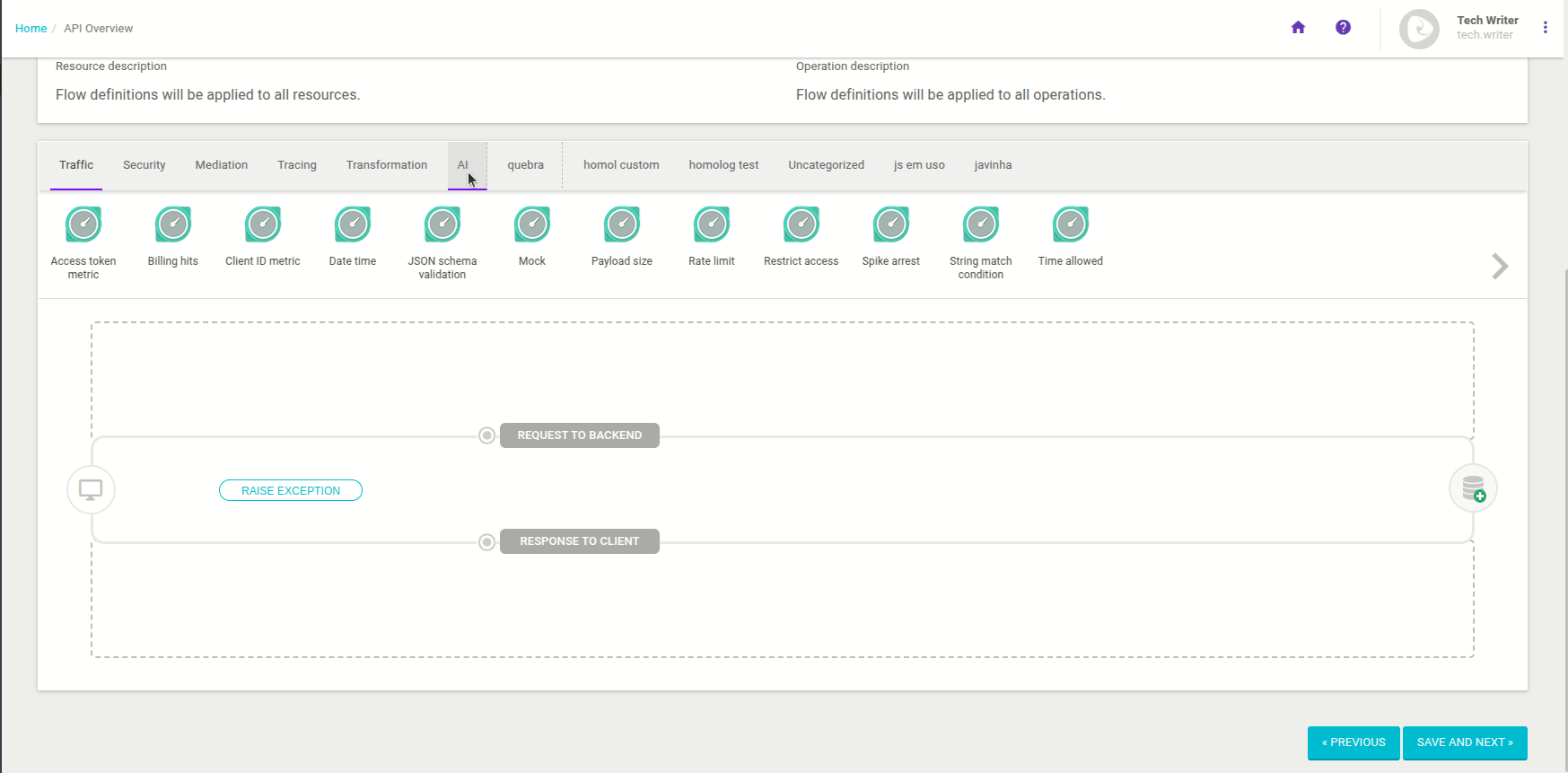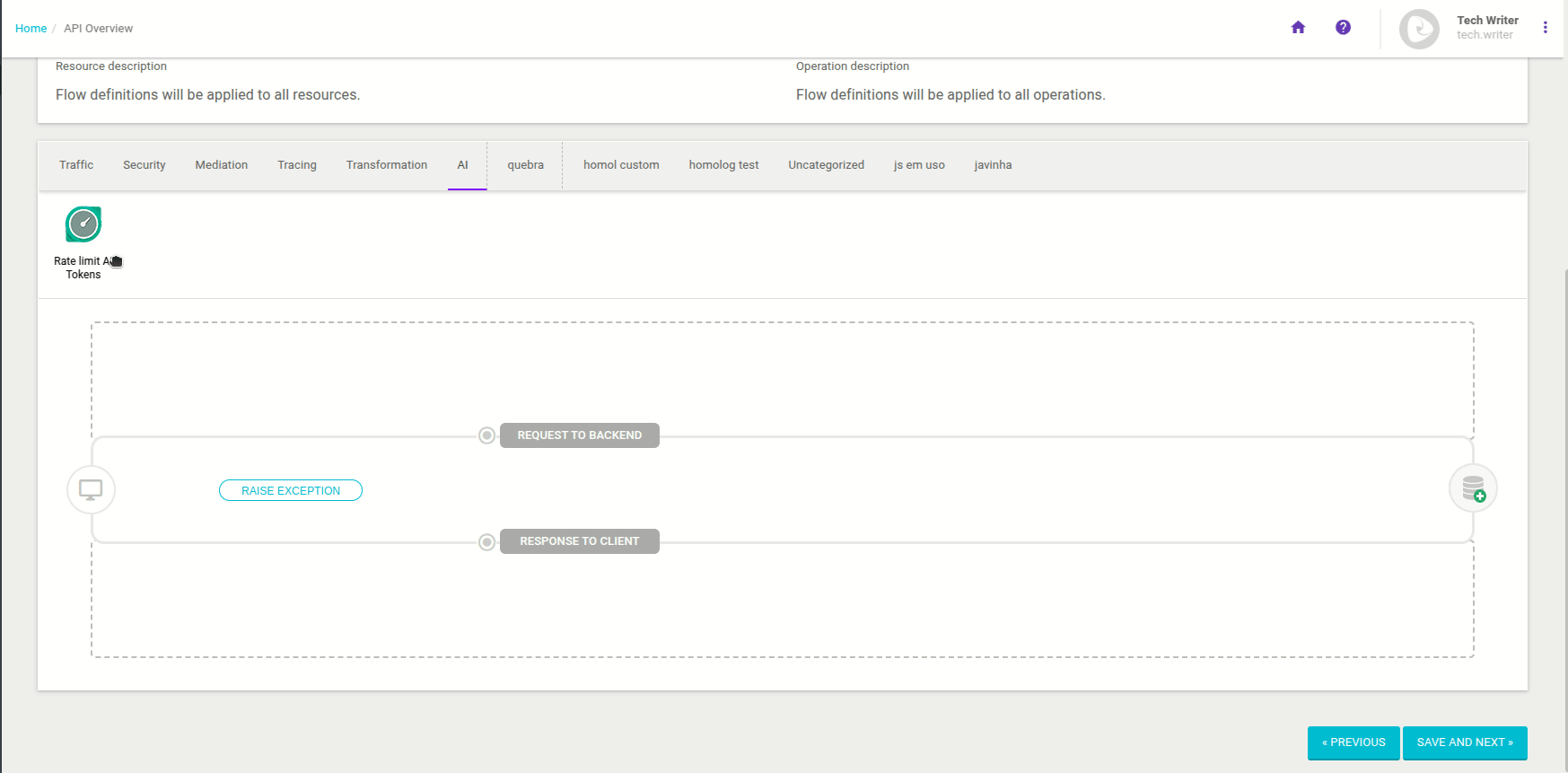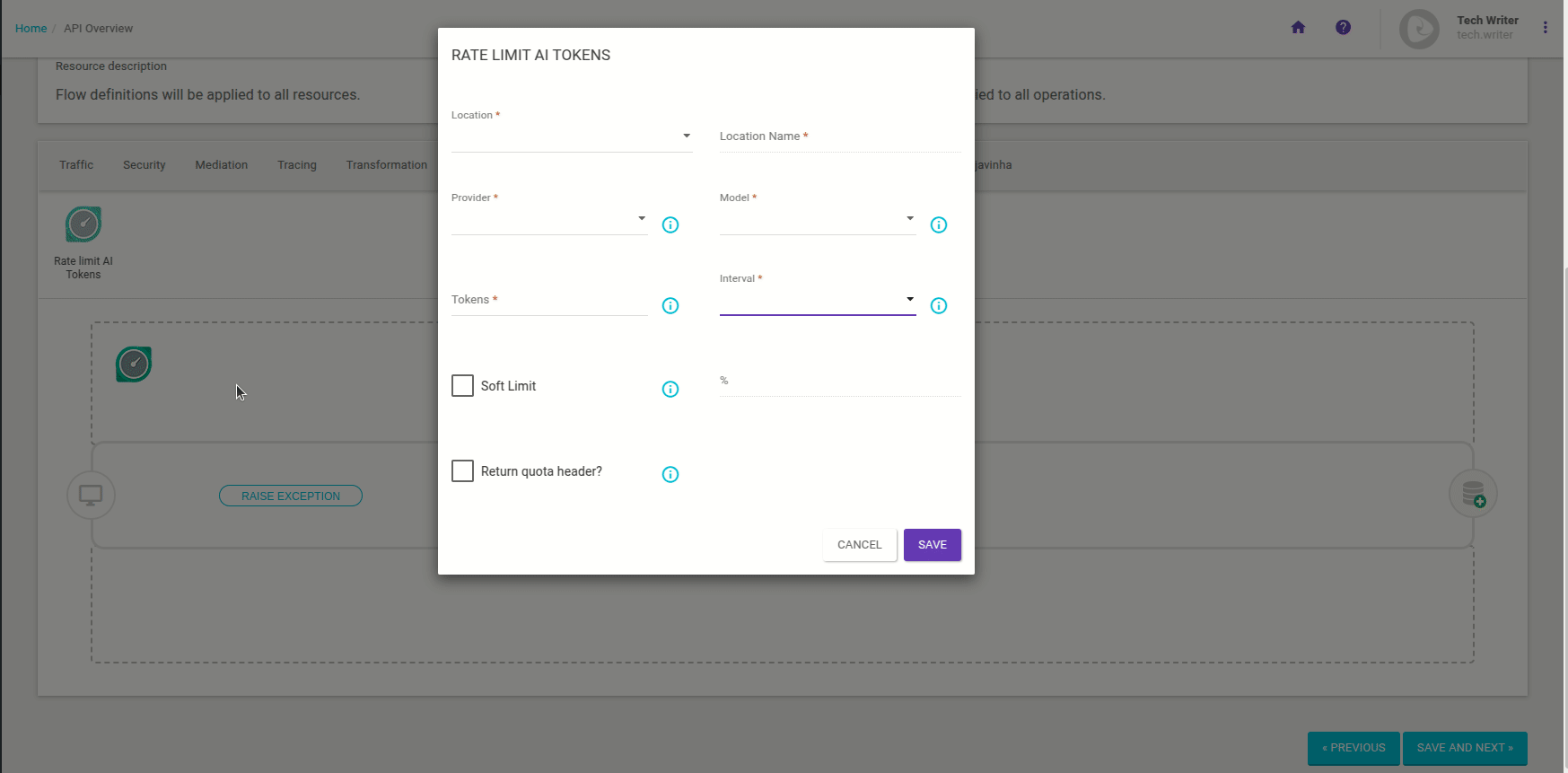
Uma janela modal se abrirá para que você forneça as seguintes informações:
Location: selecione o local na requisição onde serão enviadas as informações sobre os tokens (Cookie, Header, Query Param ou JSON Body).
Location Name: informe o nome do campo selecionado em Location.
No caso de JSON Body, você pode informar o nome exato de um campo do JSON ou utilizar expressões JSONPath, que permitem acessar campos ou arrays de forma dinâmica e flexível em estruturas JSON complexas.
Veja exemplos de uso desse campo.
Provider: selecione o provedor do LLM utilizado (no momento, apenas modelos fornecidos pela OpenAI são aceitos).
Model: selecione o LLM utilizado.
Tokens: informe o número máximo de tokens aceitos dentro do período de tempo especificado.
Interval: selecione o intervalo de tempo dentro do qual o número máximo de tokens especificado será aceito.
Soft Limit: permite definir um percentual adicional de tokens a serem aceitos. Para isso, marque a caixa de seleção e adicione o valor desejado no campo % à direita.
|
Caso a opção Soft Limit seja marcada, o campo % passa a ser obrigatório. Caso contrário, o interceptor funcionará normalmente, tendo como base o limite definido no campo Tokens. |
Return quota header?: se marcado, um parâmetro com a quantidade de tokens restantes será enviado com o header da resposta, como na imagem abaixo:
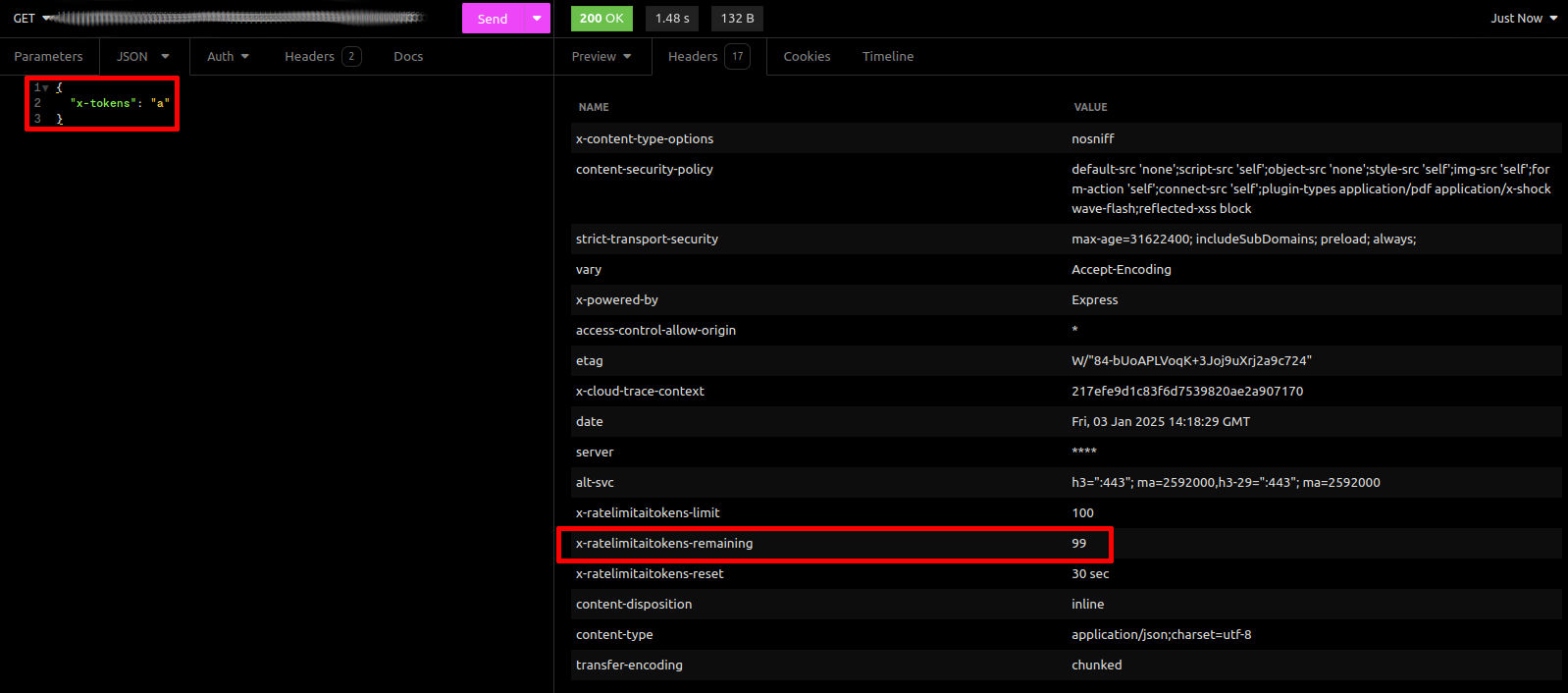
|
Qualquer tipo de dado a ser processado pelo interceptor, seja código, JSON ou texto estruturado, precisa ser convertido para string antes do envio. Caso o valor não seja uma string:
Por que o bypass ocorre? O interceptor só consegue calcular tokens para valores de tipo string. Campos que sejam arrays, objetos, valores nulos ou outros tipos não podem ser processados. Assim, para evitar falhas na requisição nesses casos, a configuração do interceptor Rate Limit AI Tokens é simplesmente ignorada. Como evitar o bypass? Certifique-se de que o campo avaliado seja sempre uma string. No caso de objetos ou arrays, use serialização ou extraia os valores necessários com ferramentas como JSONPath (veja abaixo), garantindo que o resultado seja uma string.
A contabilização de tokens não é feita diretamente em objetos ou arrays. Todo o conteúdo deve ser serializado como string, já que a própria API da OpenAI aceita apenas strings.
Caso deseje computar os tokens de um campo específico dentro de um JSON, você deve indicar claramente o campo desejado (usando o nome literal ou uma expressão JSONPath, como exemplificado a seguir). É indispensável que o valor extraído seja uma string. |
Ao selecionar JSON Body no campo Location do formulário de configuração do interceptor, haverá estas duas possibilidades para o campo Location Name:
Nome exato do campo: Informe diretamente o nome exato do campo desejado no JSON.
Expressão JSONPath: Insira uma expressão iniciada por $. para acessar dados no JSON de forma dinâmica.
Caso o valor inserido comece com $., ele será interpretado como uma expressão JSONPath.
Caso contrário, será tratado como o nome exato de um campo do JSON no nível raiz.
Veja a seguir alguns exemplos:
{
"model": "gpt-4o",
"version": "v1.0",
"content": "Qual é o clima hoje?"
}
Campo literal: content → Resultado: Qual é o clima hoje? (total: 6 tokens, 20 caracteres)
JSONPath: $.content → Resultado: Qual é o clima hoje? (total: 6 tokens, 20 caracteres)
JSON de entrada:
{
"model": "gpt-4o",
"messages": [
{
"role": "system",
"content": "Responda sempre com ironia"
},
{
"role": "user",
"content": "Aqui está um JSON, você pode me ajudar a entender os itens?\n\n{\"items\": [{\"id\": 1, \"value\": \"primeiro\"}, {\"id\": 2, \"value\": null}, {\"id\": 3}]}"
}
]
}
Campo literal: messages → Resultado: a contabilização será ignorada, pois messages é um array, e não uma string.
Campo literal: model → Resultado: gpt-4o (total: 5 tokens, 6 caracteres)
JSONPath: $.messages[*] → a contabilização será ignorada, pois messages é um array de objetos, e não uma string.
Ao se usar alternativas como $.messages[*], todo o array será retornado, o que causa um “bypass”, já que o resultado deve ser uma string.
JSONPath: $.messages[0].content → Resultado: Responda sempre com ironia (total: 7 tokens, 26 caracteres)
JSONPath: $.messages[1].content → Resultado: Aqui está um JSON, você pode me ajudar a entender os itens?\n\n{\"items\": [{\"id\": 1, \"value\": \"primeiro\"}, {\"id\": 2, \"value\": null}, {\"id\": 3}]} (total: 54 tokens, 157 caracteres)
JSONPath: $.messages[*].content → Resultado: Responda sempre com ironia + Aqui está um JSON, você pode me ajudar a entender os itens?\n\n{\"items\": [{\"id\": 1, \"value\": \"primeiro\"}, {\"id\": 2, \"value\": null}, {\"id\": 3}]} (total: 61 tokens, 183 caracteres)
JSONPath com condicional:
$.messages[?(@.role=="user")].content
messages: O nome do array no JSON.
[?(@.role=="user")]: Um filtro condicional que verifica se o campo role possui o valor "user".
@: Representa o item atual no array.
role=="user": A condição que verificamos.
.content: O campo que queremos extrair do objeto que atendeu à condição.
Resultado (total: 54 tokens, 157 caracteres):
Aqui está um JSON, você pode me ajudar a entender os itens?\n\n{\"items\": [{\"id\": 1, \"value\": \"primeiro\"}, {\"id\": 2, \"value\": null}, {\"id\": 3}]}
{
"user": {
"id": 123,
"profile": {
"name": "João",
"preferences": {
"notifications": true
}
}
}
}
Campo literal: user → a contabilização será ignorada, pois user é um objeto, e não uma string.
JSONPath: $.user.profile.name → Resultado: João (total: 2 tokens, 4 caracteres)
JSONPath: $.user.profile.preferences.notifications → Resultado: true (total: 1 token, 4 caracteres)
{
"items": [
{"id": 1, "value": "primeiro"},
{"id": 2, "value": null},
{"id": 3}
]
}
Campo literal: items → a contabilização será ignorada, pois items não é uma string.
JSONPath: $.items[*].value → Resultado: ["primeiro", null] (total: 2 tokens, 8 caracteres)
JSONPath: $.items[?(@.id==2)].value → Resultado: [null] (total: 0 tokens, 0 caracteres)
JSONPath: $.items[3].value → Resultado: Será lançada uma exceção informando que o campo não foi encontrado, correspondente a um código de status HTTP 400 (Bad Request).
Share your suggestions with us!
Click here and then [+ Submit idea]