Thanks for your feedback!
EDIT
Nesta página, fornecemos uma visão geral sobre as instruções SQL usadas na configuração da maior parte dos conectores de bancos de dados do Sensedia Integrations.
Nesta seção, você encontrará:
Uma instrução SQL é um comando ou consulta que permite interagir com bancos de dados relacionais em um fluxo de integração.
Elas são usadas para manipular dados, seja para consultar, inserir, atualizar ou excluir registros. Dessa forma, as instruções tornam-se fundamentais para a troca e gerenciamento de informações entre sistemas integrados.
Para garantir a execução correta dessas operações, cada instrução deve ser redigida de acordo com a sintaxe nativa do SQL.
Você pode utilizar as Properties, localizadas no lado esquerdo da tela, para selecionar variáveis de ambiente e payloads de steps anteriores que deseja incluir na instrução.
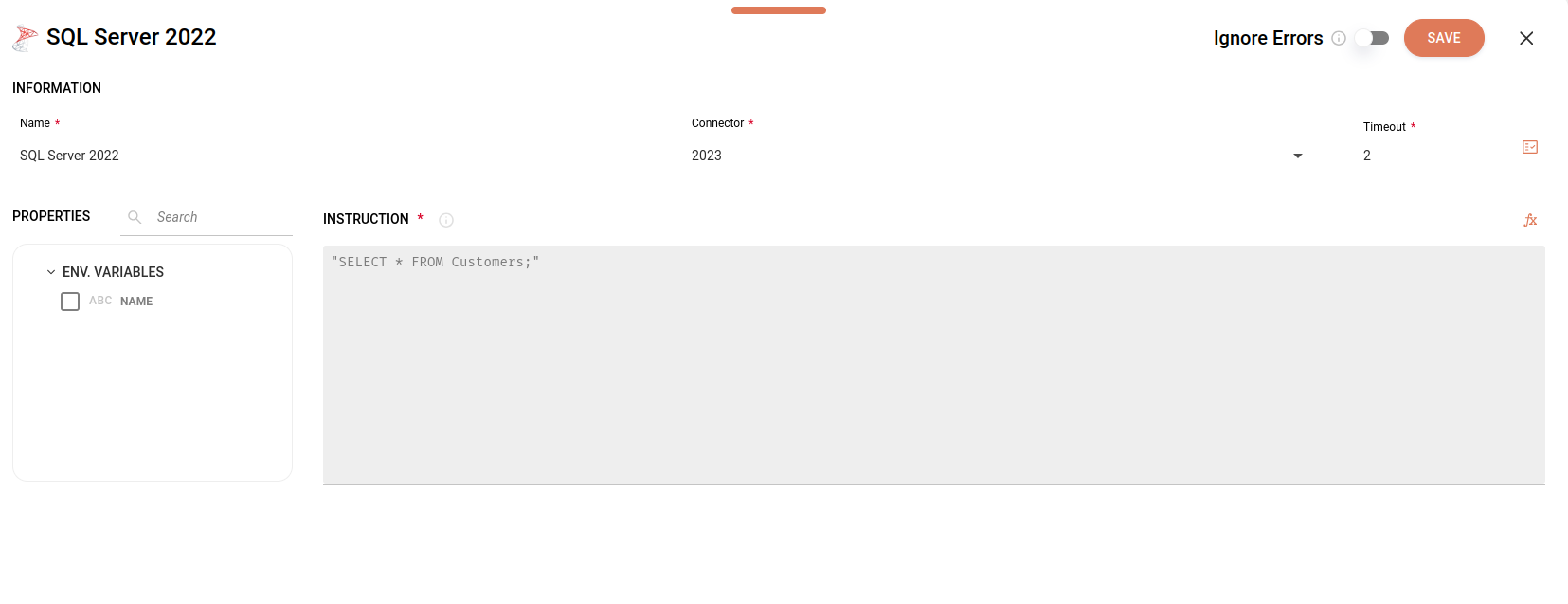
Abaixo, veja o formulário de configuração para o conector de banco de dados SQL Server 2022:
As operações SQL são instruções que realizam ações sobre os dados em um banco de dados, sendo as mais comuns SELECT, INSERT, UPDATE e DELETE.
SELECT: seleciona dados de uma ou mais tabelas.
SELECT first_name, last_name, email
FROM employees
WHERE department = 'Sales';A instrução seleciona as colunas first_name, last_name e email da tabela employees para todos os funcionários do departamento de vendas (Sales).
INSERT: adiciona novos registros a uma tabela.
INSERT INTO employees (first_name, last_name, department, hire_date)
VALUES ('John', 'Doe', 'Marketing', '2024-11-01');A instrução insere um novo registro na tabela employees, com os valores fornecidos para as colunas first_name, last_name, department e hire_date.
UPDATE: modifica os dados existentes em uma tabela.
UPDATE employees
SET department = 'Marketing', hire_date = '2024-11-01'
WHERE employee_id = 123;A instrução atualiza a tabela employees com os dados do funcionário employee_id = 123, alterando seu departamento e data de contratação.
DELETE: remove registros de uma tabela.
DELETE FROM employees
WHERE employee_id = 123;A instrução exclui o registro do funcionário com employee_id = 123 da tabela employees.
JOIN: combina registros de duas ou mais tabelas, com base em uma condição de relacionamento entre elas. Existem diferentes tipos de JOINs, como INNER JOIN, LEFT JOIN, RIGHT JOIN, e FULL JOIN.
SELECT employees.first_name, employees.last_name, departments.department_name
FROM employees
INNER JOIN departments
ON employees.department_id = departments.department_id;A instrução faz uma junção (usando INNER JOIN) entre as tabelas employees e departments.
A junção ocorre quando o valor da coluna department_id é igual nas duas tabelas.
CREATE e ALTER: definem ou modificam a estrutura do banco de dados (criando novos objetos ou alterando objetos existentes).
CREATE: cria uma nova tabela ou outro objeto.
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(100),
last_name VARCHAR(100),
department VARCHAR(50),
hire_date DATE
);A instrução cria uma tabela chamada employees, onde:
employee_id será a coluna primária e conterá apenas números inteiros (integer).
As colunas first_name e last_name devem conter uma string com até 100 caracteres.
A coluna department deve conter uma string com até 50 caracteres.
A coluna hire_date deve conter uma data.
ALTER: modifica a estrutura de uma tabela existente, como adicionar ou excluir colunas.
ALTER TABLE employees
ADD email VARCHAR(100);A instrução modifica a tabela employees adicionando a coluna email, que deve conter uma string com até 100 caracteres.
GROUP BY e HAVING: GROUP BY agrupa registros que têm valores idênticos em colunas específicas, permitindo que funções agregadas (como COUNT, SUM, AVG) sejam usadas para calcular resultados para cada grupo. HAVING é utilizado para filtrar os grupos após a aplicação do GROUP BY.
SELECT department, COUNT(*)
FROM employees
GROUP BY department
HAVING COUNT(*) > 5;Na tabela employees, a instrução seleciona os departamentos e conta o número de funcionários em cada um.
Em seguida, ela agrupa os dados por departamento e exibe apenas os departamentos que têm mais de 5 funcionários.
A seguir, confira algumas regras básicas de sintaxe para montar uma instrução:
Aspas simples (') para strings:
Strings são delimitadas por aspas simples.
Exemplo: SELECT * FROM users WHERE name = 'João';
A instrução retorna todas as colunas dos registros onde o valor da coluna name é João.
Aspas duplas (") para identificadores:
Em algumas situações é possível usar aspas duplas para identificadores de coluna ou tabela (como "id", "users"), mas isso não é obrigatório em todos os bancos de dados e pode variar.
Exemplo: SELECT "id" FROM "users";
A instrução seleciona apenas a coluna id da tabela users.
Vírgula (,):
A vírgula é usada para separar argumentos ou elementos dentro de uma função, lista de parâmetros, ou concatenação de strings.
Exemplo: SELECT id, name FROM users WHERE age > 18;
A instrução filtra os usuários da tabela users com mais de 18 anos e exibe apenas seus id e name.
Ponto e vírgula (;):
O ponto e vírgula é usado para indicar o término de um comando, o que permite que múltiplas instruções sejam executadas dentro de um mesmo bloco.
Exemplo: SELECT * FROM users; UPDATE users SET age = 30 WHERE id = 1;
A instrução retorna todas as colunas da tabela users e atualiza o valor da coluna age para 30 no registro onde o id é 1.
Escapamento de aspas internas:
Se você precisa usar aspas simples dentro de uma string que também está delimitada por aspas simples, deve escapar essas aspas internas usando outras aspas simples.
Exemplo: SELECT * FROM users WHERE name = 'O''Malley';
A instrução retorna todas as colunas dos registros onde o valor da coluna name é 'O’Malley'.
Asterisco para selecionar todas as colunas de um registro
Exemplo: SELECT * FROM orders WHERE total_amount < 100;
A instrução retorna todas as colunas da tabela orders com valor inferior a 100.
WHERE para filtragem:
A cláusula WHERE sempre é colocada após a declaração FROM para definir condições de filtragem.
Exemplo: SELECT * FROM users WHERE id = 1;
A instrução retorna todas as colunas da tabela users nas quais o id é igual a 1.
Operadores lógicos
Os operadores lógicos AND, OR, NOT são usados para combinar condições dentro da cláusula WHERE.
Exemplo: SELECT * FROM users WHERE age > 18 AND status = 'active';
A instrução retorna todas as colunas da tabela users com idade superior a 18 anos e com status active.
Operadores relacionais
Os operadores relacionais: =, !=, <, >, ⇐, >=, BETWEEN, LIKE, IN são usados para comparar valores em condições.
Exemplo: SELECT * FROM products WHERE price BETWEEN 10 AND 100;
A instrução retorna todas as colunas da tabela products, mas somente para os registros onde o valor da coluna price está dentro do intervalo de 10 a 100.
Agora, vamos explorar alguns exemplos de como aplicar instruções em diferentes contextos no Sensedia Integrations.
Exemplo 1
concat("SELECT * FROM users WHERE id = ", $.For_Each.Input.Payload.id)A instrução retorna todas as colunas da tabela users para o registro onde o id é igual ao id do payload de entrada do For Each.
.
concat: a função Concat é usada para unir (ou concatenar) duas ou mais strings em uma única string.
"SELECT * FROM users WHERE id = ": instrui o banco de dados a:
Selecionar (SELECT)
todas as colunas (*)
da (FROM)
tabela users
e filtrar a busca (WHERE)
para retornar apenas as linhas onde a coluna id corresponde a um valor específico que é indicado após o sinal de igual (id =).
$.For_Each.Input.Payload.id: valor que será filtrado pela instrução, extraído do campo id no payload de entrada do step For Each.
Exemplo 2
concat(
"INSERT INTO clients (id, name, last_name)
VALUES (",
$.For_Each.Input.Payload.id, ", '",
$.For_Each.Input.Payload.first_name, "', '",
$.For_Each.Input.Payload.last_name, "') ",
"ON DUPLICATE KEY UPDATE
name = VALUES(name),
last_name = VALUES(last_name);"
)A instrução insere um novo registro na tabela clients com os valores id, name e last_name.
Os valores específicos são retirados do payload de entrada do step For Each.
Se o id (ou outra chave primária) já existir na tabela, a instrução não insere um novo registro, mas atualiza os campos:
name
last_name
Exemplo 3
CREATE TABLE IF NOT EXISTS clients (
id INT PRIMARY KEY,
name VARCHAR(255),
last_name VARCHAR(255)
);A instrução é um comando CREATE TABLE, que cria uma tabela no banco de dados.
IF NOT EXISTS: esta cláusula garante que a tabela seja criada somente se ela ainda não existir.
A tabela se chamará clients, e será usada para armazenar informações de clientes.
A seguir temos as definições das 3 colunas:
id INT PRIMARY KEY: o nome da coluna será id e o tipo de dado a ser inserido na coluna será número inteiro (integer).
Essa será a coluna primária, o que significa que deve conter valores únicos e não nulos.
name VARCHAR(255): o nome da coluna será name e o tipo de dado a ser inserido na coluna é uma string com até 255 caracteres.
O tipo VARCHAR é usado para armazenar textos curtos.
last_name VARCHAR(255): o nome da coluna será last_name e possui as mesmas características da segunda coluna.
Exemplo 4
concat(
"DECLARE ",
"v_json CLOB := '", $.CombinarDados.Response.Payload, "';",
"BEGIN ",
"INSERT_PROCEDURE_DATA(v_json);",
"END;"
)A instrução se inicia com a função concat, que é usada para montar dinamicamente um comando PL/SQL (a linguagem de programação do Oracle) que executa as etapas abaixo:
Declara (declare) uma variável v_json do tipo CLOB (Character Large Object).
O tipo CLOB é usado para armazenar grandes volumes de texto, como documentos ou payloads grandes.
Atribui à variável o valor extraído de um payload (CombinarDados.Response.Payload).
É esperado que o payload seja um grande bloco de texto ou dados, por isso o valor é inserido entre aspas simples.
Após a declaração da variável, o comando BEGIN inicia o bloco de execução do PL/SQL, onde a lógica real da execução ocorrerá.
Dentro desse bloco, é chamado o procedimento INSERT_PROCEDURE_DATA, que recebe a variável v_json como argumento para processar ou inserir os dados no banco de dados.
O bloco é finalizado com o comando END, encerrando a execução da sequência de instruções.
| Um procedimento é um conjunto de instruções SQL que ficam armazenadas no banco de dados e podem ser executadas repetidamente. |
Share your suggestions with us!
Click here and then [+ Submit idea]